How to Scrape Competitor Prices: DIY Tools, Trade-offs, and When to Buy Instead
Scraping a price is easy. Keeping thousands of products matched to the right competitor, every day, is the hard part. A practical guide to the DIY tools — Python libraries, AI scrapers, no-code extensions — when they're the right call, and when they quietly cost more than they save.
If you sell online, you already know your prices aren't set in a vacuum. A competitor drops theirs, a marketplace seller undercuts you, and suddenly your bestseller isn't moving. So you decide to start tracking competitor prices — and the first question is always the same: do you build a scraper yourself, or pay for a tool that does it for you?
This is a practical guide to that decision: how price scraping actually works, the tools that do the job, when building your own is the right call, and the point where it quietly starts costing more than it saves. (We make a pricing tool, so we're not a neutral party — but DIY genuinely wins for some stores, and we'll point out where.)
How price scraping actually works
Every price scraper — whether it's ten lines of Python or a commercial platform — does the same four things.
- Fetch the page. Send a request to a product URL and download its HTML, the same thing your browser does when you open it.
- Render it, if needed. Many modern stores load the price with JavaScript after the page arrives, so the raw HTML is empty where the price should be. To read it, you have to run the page in a real browser engine.
- Extract the data. Pull out the price, currency, and stock status — then normalize it (sale vs. original price, per-unit vs. multipack, AED vs. SAR) so the numbers are comparable.
- Match and monitor. Tie each price to the right product in your own catalog, then repeat on a schedule and track how it moves over time.
Steps one to three are largely a solved problem — good libraries exist and they're free. Step four is where most projects, DIY or not, quietly run into trouble. More on that shortly.
The DIY route: the tools that do the job
The toolkit splits into two halves: battle-tested code libraries if you (or someone on your team) write Python, and a newer wave of AI-assisted and no-code tools that lower the barrier to entry. Start with the classics:
- requests + BeautifulSoup — the classic starting point. requests fetches the HTML; BeautifulSoup parses it so you can pull the price out with a CSS selector. Ideal for simple, static product pages — you can have a working scraper for one site in an afternoon.
- Scrapy — a full crawling framework, not just a fetcher. It handles following links, concurrency, retries, and pipelines for cleaning and storing data. This is what you reach for when you're scraping many products across many pages and want structure instead of a pile of scripts.
- Playwright or Selenium — these drive a real, headless browser, so they can see prices that only appear after JavaScript runs. Heavier and slower than requests, but often the only thing that works on a modern storefront.
More recently, a few tools have made scraping faster to start — especially on JavaScript-heavy sites that used to demand a full browser setup:
- Firecrawl — an API (open-source, with a paid hosted tier) that turns a URL, or a whole site, into clean structured data or Markdown, handling rendering and much of the anti-bot friction for you. Useful when you'd rather call a service than run and maintain browsers yourself.
- browser-use — an open-source library that points an AI agent at a real browser and lets it follow plain-language instructions ("find the price on this page"). It adapts to layouts it hasn't seen before, which is promising for messy or inconsistent sites — though it's slower, costs LLM tokens, and is less predictable than fixed selectors.
- Instant Data Scraper — a free Chrome extension that auto-detects tables and lists on a page and exports them to CSV in two clicks. No code at all, ideal for a quick one-off pull from a few pages. It's only lightly maintained and struggles with heavily JavaScript-rendered content, so treat it as a starting point, not a monitoring setup.
Whichever route you take, a recurring price feed still usually needs rotating proxies (so you're not blocked or rate-limited from a single IP), a way past anti-bot defenses like Cloudflare (some of the newer tools bundle this), and a scheduler — a cron job, say — to re-run everything daily. None of it is exotic; it's all well-trodden ground.
When building your own is the right call
DIY scraping genuinely makes sense in a specific situation. Reach for it when most of these are true:
- You have a developer — you, or someone on the team who's comfortable in Python and won't mind owning this.
- You're tracking a small, fixed set of competitors — a handful of sites, not dozens.
- Those sites are relatively simple and stable — static HTML, prices in the markup, layouts that don't change every quarter.
- You mainly need the raw numbers — a sheet or dashboard of competitor prices — and you'll do the analysis yourself.
- You're okay with the occasional gap — if a scraper breaks for a few days after a redesign, that's an annoyance, not a crisis.
If that's you, build it. You'll save money, keep full control, and the tools above are more than good enough.
Where DIY quietly gets expensive
The real cost of a scraper isn't the afternoon you spend writing it — it's everything after. Two costs tend to creep up before you've noticed.
Sites change, and your scraper doesn't know. A competitor tweaks their page, the selector you relied on stops matching, and your scraper silently returns nothing — or worse, the wrong number. Every redesign is a maintenance ticket, and you usually find out only when a price looks off. Multiply that by every site you track.
Anti-bot and JavaScript turn a script into infrastructure. The moment a target leans on Cloudflare, aggressive rate limits, or JavaScript-rendered prices, your tidy script grows into a fleet of headless browsers behind rotating proxies. That's real money and real ops work, every month, just to keep collecting the same data.
The hard part: matching products to your catalog
Everything so far is about collecting prices. The harder problem — the one that quietly sinks most DIY projects — is making those prices mean something.
Scraping a price is easy. Knowing that the price you scraped is for the same product you sell is the hard part. Competitors list the same item under a different name, in a different language, in a bundle, or as a slightly different variant. Barcodes are missing or wrong. In this region you're regularly matching an Arabic product title to an English one, or a mixed-language listing, across stores that each describe things their own way.
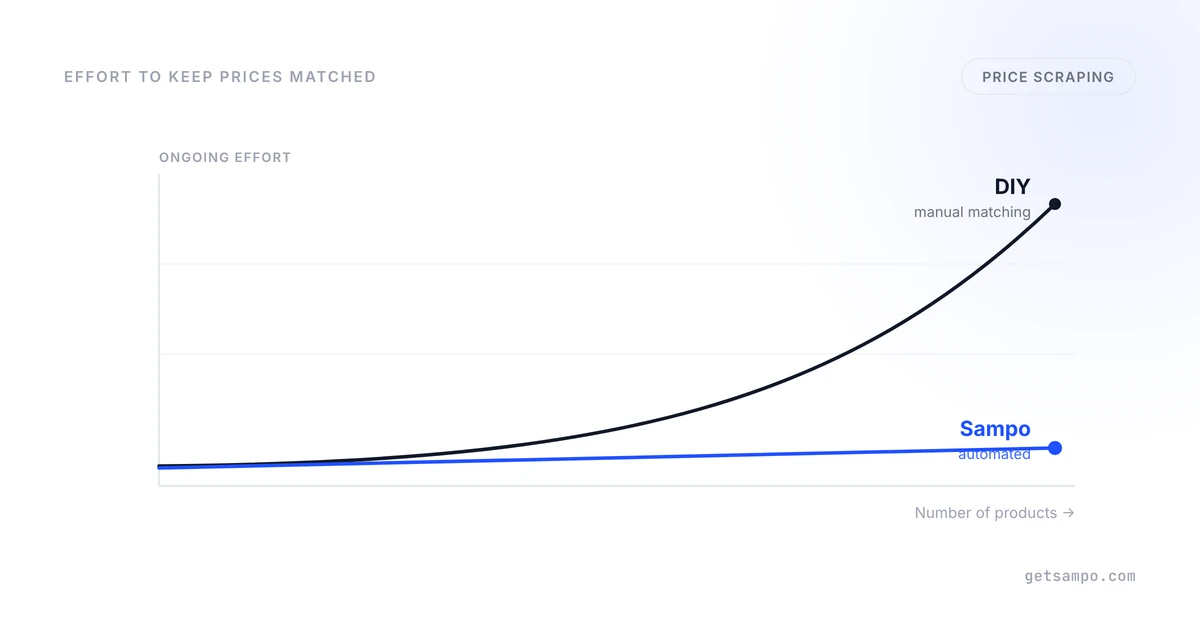
So someone matches products by hand — your SKU to their listing, one by one — and then re-checks those matches as catalogs change. With twenty products, that's a quiet afternoon. With two thousand SKUs across eight competitors, it's a permanent part-time job that never finishes. This is the moment a DIY project usually stops being free: not the scraping — the matching.
And even perfectly matched data is still just data. It doesn't tell you which prices to change, by how much, or whether last week's change actually helped — that thinking is still yours to do.
When a done-for-you tool makes more sense
A managed tool isn't automatically the answer — but it earns its keep once the costs above start to bite. It's usually the better call when:
- You have many SKUs — hundreds or thousands — where manual matching simply doesn't scale.
- You don't have a developer to spare, or you'd rather they worked on your product than on babysitting scrapers.
- You need to cover marketplaces and tough targets — Noon, Amazon.ae/.sa, sites behind Cloudflare — without running your own proxy and browser fleet.
- You're matching across Arabic and mixed-language catalogs, where naive name-matching falls apart.
- You want decisions, not just data — what to charge, and proof it worked — rather than another spreadsheet to interpret.
This is the gap Sampo is built to close: it matches your catalog to competitors automatically — Arabic titles included — keeps the scrapers running when sites change, covers Noon and Amazon, and turns the prices into pricing recommendations you can act on. It's built for the MENA market specifically, which is where most global tools struggle. We mention it because it's what we build — but the real test is the checklist above, whoever you end up buying from.
A simple way to decide
Strip away the detail and it comes down to two questions: how many products do you need to keep matched, and who's going to maintain it?
- Few products, a developer on hand, simple sites → build it yourself. The free libraries are excellent and you keep full control.
- Many products, no spare engineering time, marketplaces and Arabic in the mix → a managed tool almost always beats the manual-matching treadmill, once you count the hours it really takes.
- Somewhere in between → start with a small DIY scraper for your top few competitors and watch the matching workload. The day it starts eating real hours every week is the day the maths flips.
Either way, the thing to budget for isn't the scraping. It's the matching, the maintenance, and turning data into decisions. Get clear on who owns those three, and the build-or-buy question usually answers itself.